# PyTorch의 적절한 버전이 이미 설치되어 있다고 가정합니다.
pip install -q torchaudio omegaconf soundfile
import torch
import zipfile
import torchaudio
from glob import glob
device = torch.device('cpu') # gpu에서도 잘 돌아가지만, cpu에서도 충분히 빠릅니다.
model, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_stt',
language='en', # 'de', 'es'도 사용 가능
device=device)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils # 자세한 내용은 함수 시그니처(function signature)를 참조하세요.
# TorchAudio와 호환되는 형식(사운드 파일 백엔드)중 하나의 파일 다운로드
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav',
dst ='speech_orig.wav', progress=True)
test_files = glob('speech_orig.wav')
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]),
device=device)
output = model(input)
for example in output:
print(decoder(example.cpu()))
모델 설명
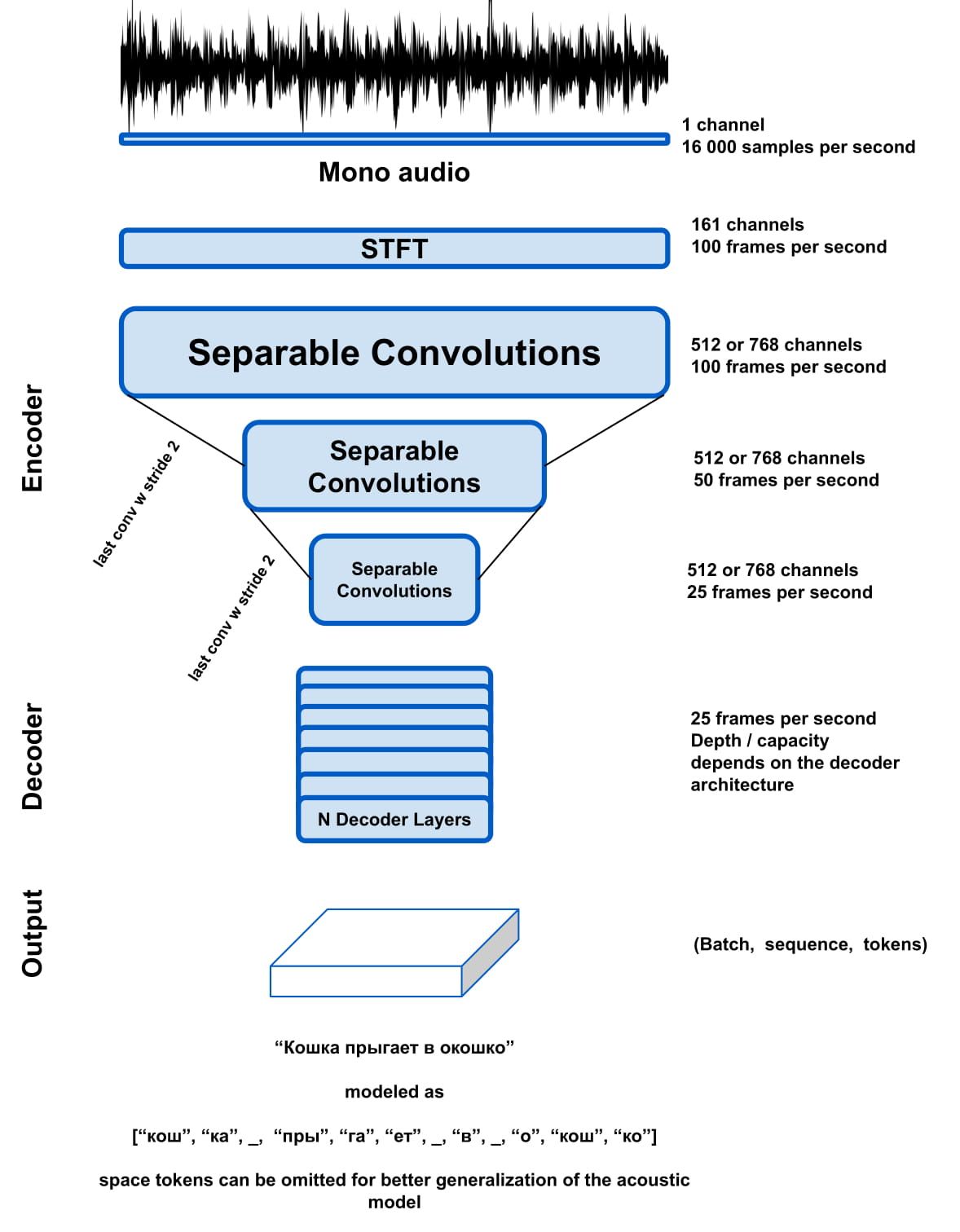
Silero Speech-To-Text 모델은 일반적으로 사용되는 여러 언어에 대해 소형 폼 팩터 형태로 엔터프라이즈급 STT를 제공합니다. 기존 ASR 모델과 달리 다양한 방언, 코덱, 도메인, 노이즈, 낮은 샘플링 속도에 강인합니다(단순화를 위해 오디오는 16kHz로 다시 샘플링해야 함). 모델은 샘플 형태의 정규화된 오디오(즉, [-1, 1] 범위로의 정규화를 제외한 어떤 전처리 없이)와 토큰 확률이 있는 출력 프레임을 사용합니다. 단순화를 위해 디코더 도구를 제공합니다. 모델 자체에 포함할 수 있지만 자막이 결합된 모듈은, 특정한 내보내기 상황에서 레이블같은 모델의 생성물을 저장할 때 문제가 있었습니다.
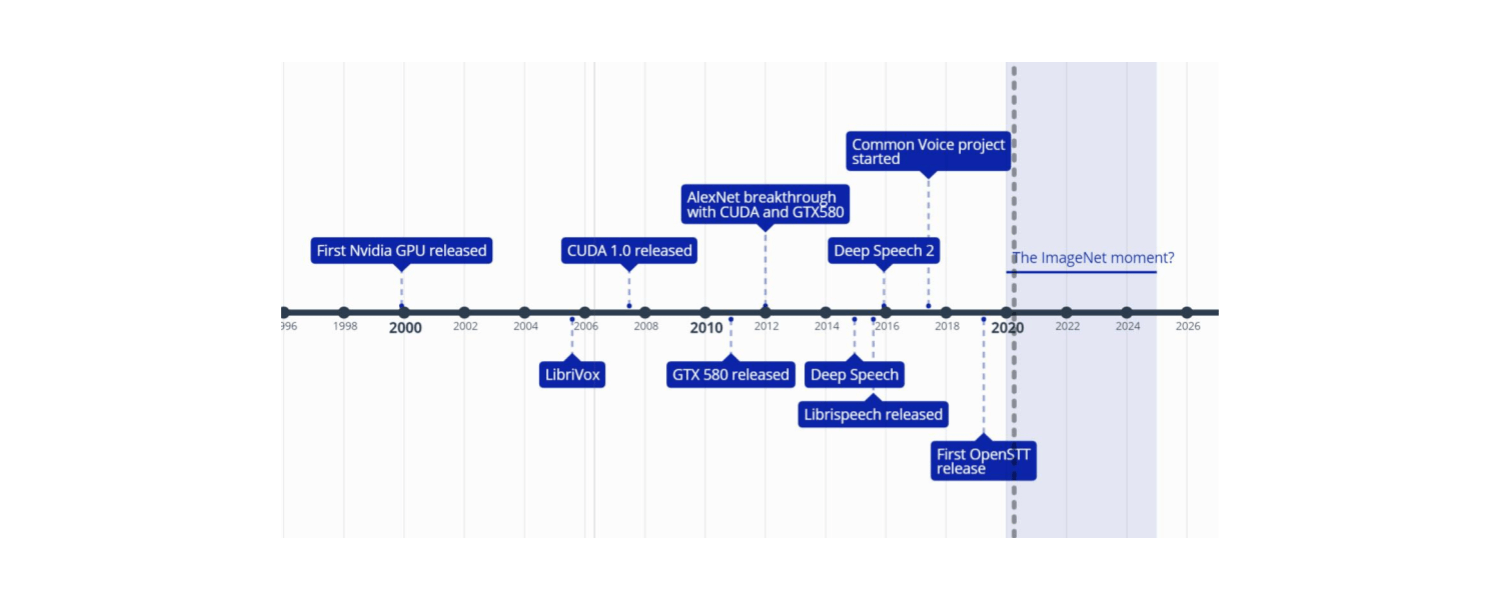
Speech에서 Open-STT와 Silero Models에 대한 노력이 ImageNet 같은 순간에 다가가길 바랍니다.
지원되는 언어 및 형식
지원되는 언어는 다음과 같습니다.
- English
- German
- Spanish
항상 최신 지원 언어 목록을 보려면 repo를 방문하여 사용 가능한 체크포인트에 대한 yml file을 확인하십시오 .
To see the always up-to-date language list, please visit our repo and see the yml file for all available checkpoints.
추가 예제 및 벤치마크
추가 예제 및 기타 모델 형식을 보려면 이 link를 방문하십시오. 품질 및 성능 벤치마크는 wiki를 참조하십시오. 관련 자료는 수시로 업데이트됩니다.
참고문헌
- Silero Models
- Alexander Veysov, “Toward’s an ImageNet Moment for Speech-to-Text”, The Gradient, 2020
- Alexander Veysov, “A Speech-To-Text Practitioner’s Criticisms of Industry and Academia”, The Gradient, 2020