
import torch
model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg11', pretrained=True)
# 추가로 아래와 같이 변형된 구조의 모델들이 있습니다
# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg11_bn', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg13', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg13_bn', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg16', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg16_bn', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg19', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg19_bn', pretrained=True)
model.eval()
모든 사전 훈련된 모델은 훈련때와 같은 방식으로 정규화된 입력 이미지를 주어야합니다.
즉, (3 x H x W) 모양의 3채널 RGB 이미지의 미니배치에서 H와 W는 최소 224가 될 것으로 예상됩니다.
이미지는 [0, 1] 범위로 로드한 다음(RGB 채널마다 0~255값으로 표현되므로 이미지를 255로 나눔) mean = [0.485, 0.456, 0.406]과 std = [0.229, 0.224, 0.225] 값을 사용하여 정규화해야 합니다.
다음은 샘플 실행입니다.
# 파이토치 웹사이트에서 예제 이미지를 다운로드 합니다
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# 샘플 실행 (torchvision이 필요합니다)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # 모델의 입력값에 맞춘 미니 배치 생성
# 가능하면 속도를 위해서 입력과 모델을 GPU로 이동 합니다
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Imagenet의 1000개 클래스에 대한 신뢰도 점수가 있는 1000개의 Tensor입니다.
print(output[0])
# 출력에 정규화되지 않은 점수가 있습니다. 확률을 얻으려면 소프트맥스를 실행할 수 있습니다.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
print(probabilities)
# ImageNet 라벨 다운로드
!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
# 카테고리 읽기
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Show top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
모델 설명
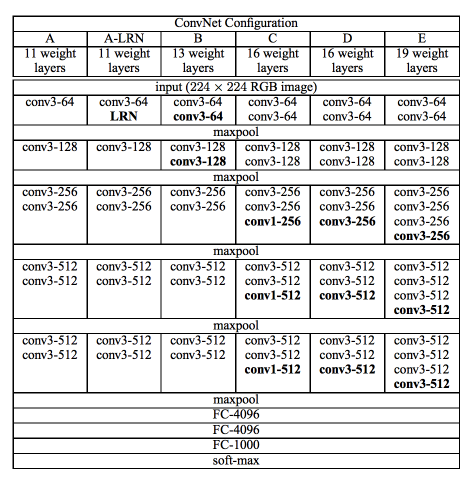
각 구성 및 bachnorm 버전에 대해서 Very Deep Convolutional Networks for Large-Scale Image Recognition에서 제안한 모델에 대한 구현이 있습니다.
예를 들어, 논문에 제시된 구성 A는 vgg11, B는 vgg13, D는 vgg16, E는 vgg19입니다.
batchnorm 버전은 _bn이 접미사로 붙어있습니다.
사전 훈련된 모델이 있는 imagenet 데이터 세트의 1-crop 오류율은 아래에 나열되어 있습니다.
| Model structure | Top-1 error | Top-5 error |
|---|---|---|
| vgg11 | 30.98 | 11.37 |
| vgg11_bn | 26.70 | 8.58 |
| vgg13 | 30.07 | 10.75 |
| vgg13_bn | 28.45 | 9.63 |
| vgg16 | 28.41 | 9.62 |
| vgg16_bn | 26.63 | 8.50 |
| vgg19 | 27.62 | 9.12 |
| vgg19_bn | 25.76 | 8.15 |