timm 종속 패키지 설치가 필요합니다.
!pip install timm
import torch
# 모델 종류: 'mealv1_resnest50', 'mealv2_resnest50', 'mealv2_resnest50_cutmix', 'mealv2_resnest50_380x380', 'mealv2_mobilenetv3_small_075', 'mealv2_mobilenetv3_small_100', 'mealv2_mobilenet_v3_large_100', 'mealv2_efficientnet_b0'
# 사전에 학습된 "mealv2_resnest50_cutmix"을 불러오는 예시입니다.
model = torch.hub.load('szq0214/MEAL-V2','meal_v2', 'mealv2_resnest50_cutmix', pretrained=True)
model.eval()
사전에 학습된 모든 모델은 동일한 방식으로 정규화된 입력 이미지, 즉, H 와 W 는 최소 224 이상인 (3 x H x W) 형태의 3-채널 RGB 이미지의 미니 배치를 요구합니다. 이미지를 [0, 1] 범위에서 불러온 다음 mean = [0.485, 0.456, 0.406] 과 std = [0.229, 0.224, 0.225] 를 통해 정규화합니다.
실행 예시입니다.
# 파이토치 웹사이트에서 예제 이미지 다운로드
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# 실행 예시 (torchvision 필요)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # 모델에서 요구하는 미니배치 생성
# 가능하다면 속도를 위해 입력과 모델을 GPU로 옮깁니다.
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# 1000개의 ImageNet 클래스에 대한 신뢰도 점수(confidence score)를 가진 1000 크기의 Tensor
print(output[0])
# output엔 정규화되지 않은 신뢰도 점수가 있습니다. 확률값을 얻으려면 softmax를 실행하세요.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
print(probabilities)
# ImageNet 레이블 다운로드
!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
# 카테고리 읽기
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# 이미지별 Top5 카테고리 조회
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
모델 설명
MEAL V2 모델들은 MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks 논문에 기반합니다.
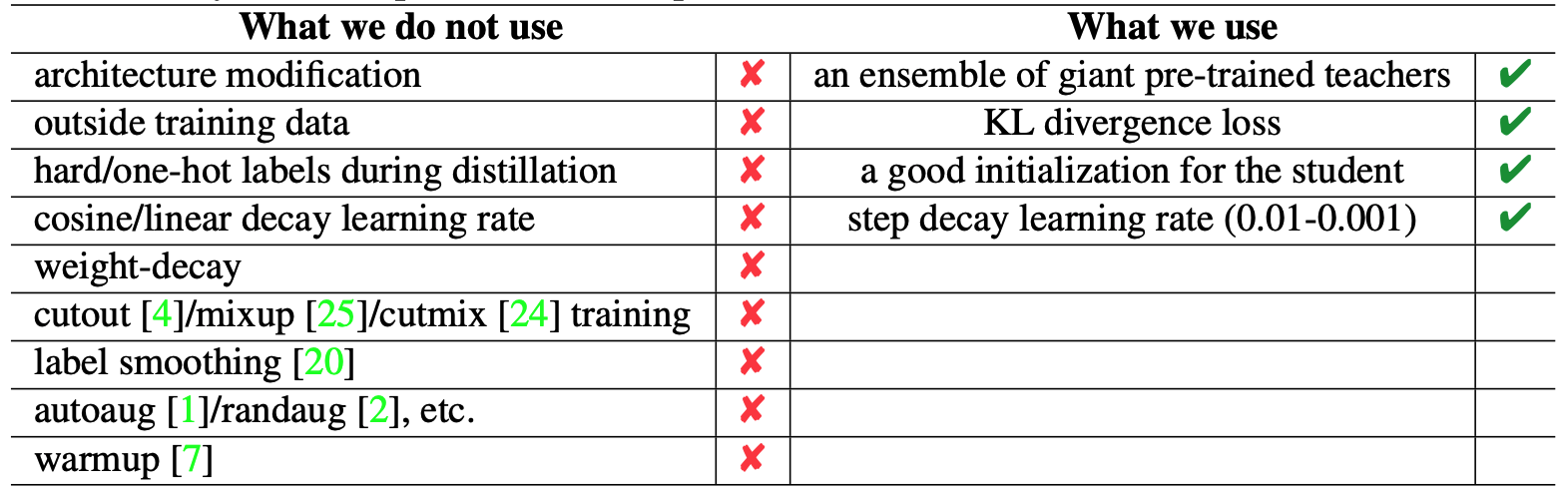
MEAL V2의 주요 관점은 distillation 과정에 One-Hot 레이블을 사용하지 않는다는 것입니다. MEAL V2는 판별자를 이용한 knowledge distillation 앙상블 기법인 MEAL에 기초하며, MEAL을 단순화하기 위해 다음의 수정을 거쳤습니다. 1) 판별자 입력, 유사도 손실 계산에 최종 출력만을 활용합니다. 2) 모든 teacher들의 예측 확률을 평균 내어 distillation에 활용합니다. 이를 통해 MEAL V2는 어떠한 트릭 사용 없이도 ResNet-50의 ImageNet Top-1 정확도를 80% 이상 기록할 수 있습니다. (트릭 : 1) 모델 구조 변경; 2) ImageNet 외 추가 데이터 활용; 3) autoaug/randaug; 4) cosine learning rate; 5) mixup/cutmix; 6) label smoothing; etc)
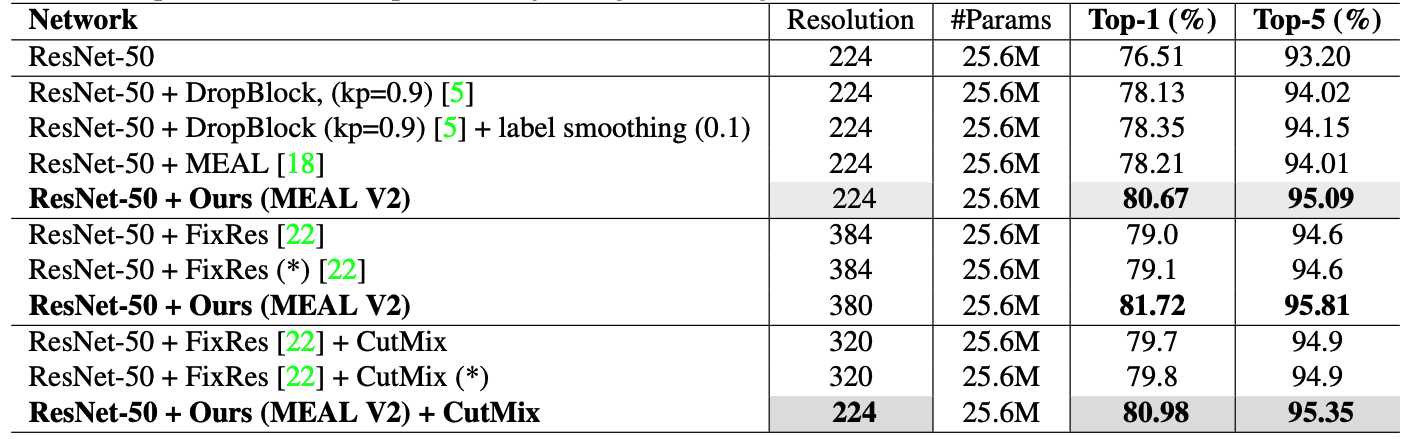
| Models | Resolution | #Parameters | Top-1/Top-5 | |
|---|---|---|---|---|
| MEAL-V1 w/ ResNet50 | 224 | 25.6M | 78.21/94.01 | GitHub |
| MEAL-V2 w/ ResNet50 | 224 | 25.6M | 80.67/95.09 | |
| MEAL-V2 w/ ResNet50 | 380 | 25.6M | 81.72/95.81 | |
| MEAL-V2 + CutMix w/ ResNet50 | 224 | 25.6M | 80.98/95.35 | |
| MEAL-V2 w/ MobileNet V3-Small 0.75 | 224 | 2.04M | 67.60/87.23 | |
| MEAL-V2 w/ MobileNet V3-Small 1.0 | 224 | 2.54M | 69.65/88.71 | |
| MEAL-V2 w/ MobileNet V3-Large 1.0 | 224 | 5.48M | 76.92/93.32 | |
| MEAL-V2 w/ EfficientNet-B0 | 224 | 5.29M | 78.29/93.95 |
참조
자세한 사항은 MEAL V2, MEAL을 통해 확인할 수 있습니다.
@article{shen2020mealv2,
title={MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks},
author={Shen, Zhiqiang and Savvides, Marios},
journal={arXiv preprint arXiv:2009.08453},
year={2020}
}
@inproceedings{shen2019MEAL,
title = {MEAL: Multi-Model Ensemble via Adversarial Learning},
author = {Shen, Zhiqiang and He, Zhankui and Xue, Xiangyang},
booktitle = {AAAI},
year = {2019}
}