import torch
model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet68', pretrained=True)
# or any of these variants
# model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet85', pretrained=True)
# model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet68ds', pretrained=True)
# model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet39ds', pretrained=True)
model.eval()
모든 사전 훈련된 모델은 동일한 방식으로 정규화된 입력 이미지를 요구합니다.
즉, H와 W가 최소 224의 크기를 가지는 (3 x H x W)형태의 3채널 RGB 이미지의 미니배치가 필요합니다.
이미지를 [0, 1] 범위로 불러온 다음 mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]를 이용하여 정규화해야 합니다.
다음은 실행예시입니다.
# 파이토치 웹 사이트에서 예제 이미지 다운로드
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# 실행예시 (torchvision이 요구됩니다)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # 모델에서 요구하는 미니배치 생성
# GPU 사용이 가능한 경우 속도를 위해 입력과 모델을 GPU로 이동
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# ImageNet의 1000개 클래스에 대한 신뢰도 점수를 가진 1000 형태의 Tensor 출력
print(output[0])
# 출력은 정규화되어있지 않습니다. 소프트맥스를 실행하여 확률을 얻을 수 있습니다.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
print(probabilities)
# ImageNet 레이블 다운로드
!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
# 카테고리 읽어오기
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# 이미지마다 상위 카테고리 5개 보여주기
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
모델 설명
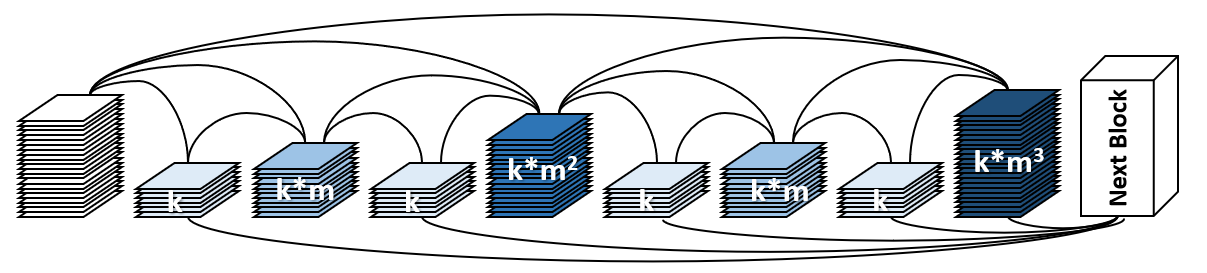
HarDNet(Harmonic DenseNet)은 낮은 메모리 트래픽을 가지는 CNN 모델로 빠르고 효율적입니다. 기본 개념은 계산 비용과 메모리 접근 비용을 동시에 최소화하는 것입니다. 따라서 HarDNet 모델은 동일한 정확도를 가진 ResNet 모델에 비해 GPU에서 실행되는 속도가 35% 더 빠릅니다. (MobileNet과 비교하기 위해 설계된 두 DS 모델은 제외)
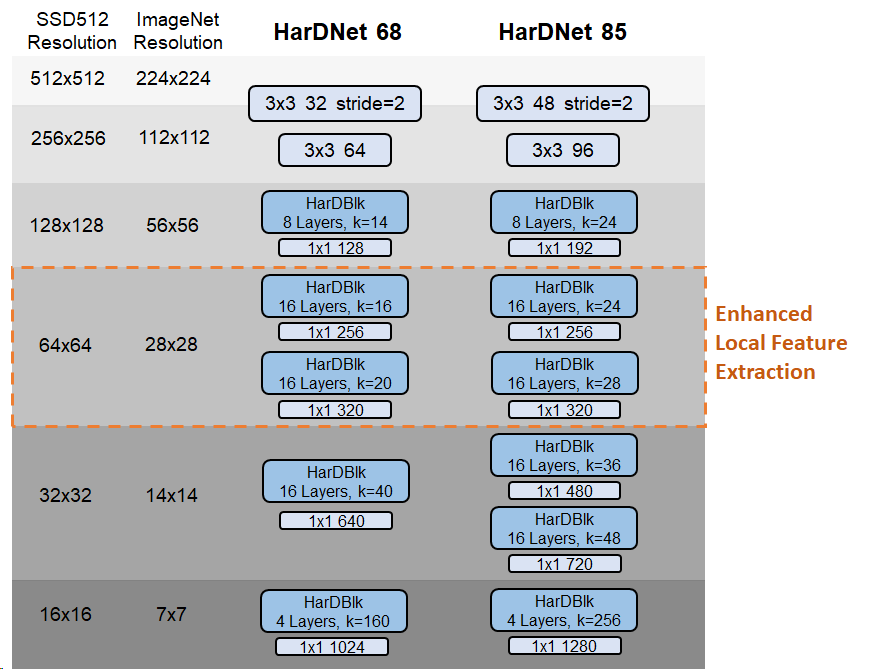
아래에는 각각 깊이별 분리 가능한 Conv 레이어가 있거나 없는 39, 68, 85개의 레이어를 포함한 4가지 버전의 HardNet 모델이 있습니다. 사전 훈련된 모델에 대해 ImageNet 데이터셋의 1-crop 오류율은 아래에 나열되어 있습니다.
| Model structure | Top-1 error | Top-5 error |
|---|---|---|
| hardnet39ds | 27.92 | 9.57 |
| hardnet68ds | 25.71 | 8.13 |
| hardnet68 | 23.52 | 6.99 |
| hardnet85 | 21.96 | 6.11 |