
모델 설명
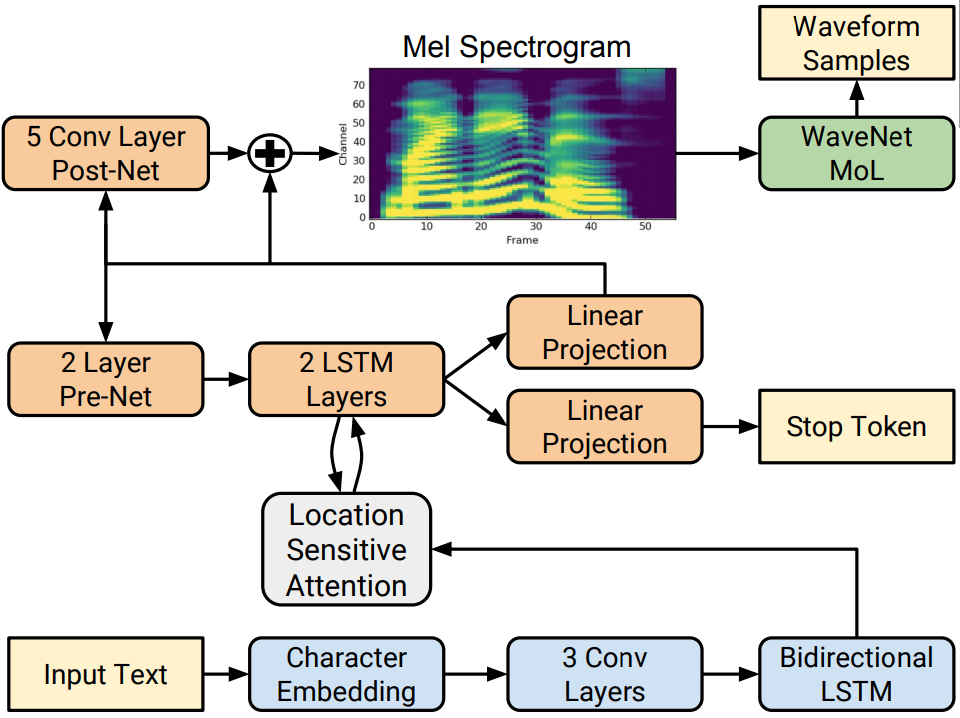
Tacotron 2 및 WaveGlow 모델은 추가 운율 정보 없이 원본 텍스트에서 자연스러운 음성을 합성할 수 있는 텍스트 음성 변환 시스템을 만듭니다. Tacotron 2 모델은 인코더-디코더 아키텍처를 사용하여 입력 텍스트에서 멜 스펙트로그램(mel spectrogram)을 생성합니다. WaveGlow (torch.hub를 통해서도 사용 가능)는 멜 스펙트로그램을 사용하여 음성을 생성하는 흐름 기반(flow-based) 모델입니다.
사전 훈련된 Tacotron 2 모델은 논문과 다르게 구현되었습니다. 여기서 제공하는 모델에서는 LSTM 레이어를 정규화하기 위해 Zoneout 대신 Dropout을 사용합니다.
예시 사례
아래 예제에서는:
- 사전 훈련된 Tacotron2 및 Waveglow 모델은 torch.hub에서 가져옵니다.
- Tacotron2는 (“Hello world, I miss you so much”)와 같은 입력 텍스트의 텐서 표현이 주어지면 그림과 같은 멜 스펙트로그램을 생성합니다.
- Waveglow는 멜 스펙트로그램에서 사운드를 생성합니다.
- 출력 사운드는 ‘audio.wav’ 파일에 저장됩니다.
이 예제를 실행하려면 몇 가지 추가 파이썬 패키지가 설치되어 있어야 합니다. 이는 텍스트 및 오디오를 전처리하는 것은 물론 디스플레이 및 입출력 전처리에도 필요합니다.
pip install numpy scipy librosa unidecode inflect librosa
apt-get update
apt-get install -y libsndfile1
LJ Speech dataset 데이터셋에서 사전 훈련된 Tacotron2 모델을 불러오고 추론을 준비합니다.
import torch
tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp16')
tacotron2 = tacotron2.to('cuda')
tacotron2.eval()
사전 훈련된 WaveGlow 모델 불러오기
waveglow = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_waveglow', model_math='fp16')
waveglow = waveglow.remove_weightnorm(waveglow)
waveglow = waveglow.to('cuda')
waveglow.eval()
모델이 다음과 같이 말하게 합시다.
text = "Hello world, I missed you so much."
유틸리티 메서드를 사용하여 입력 형식을 지정합니다.
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')
sequences, lengths = utils.prepare_input_sequence([text])
연결된 모델을 실행합니다.
with torch.no_grad():
mel, _, _ = tacotron2.infer(sequences, lengths)
audio = waveglow.infer(mel)
audio_numpy = audio[0].data.cpu().numpy()
rate = 22050
파일로 저장하여 들어볼 수 있습니다.
from scipy.io.wavfile import write
write("audio.wav", rate, audio_numpy)
또는 IPython이 있는 노트북에서 바로 들어볼 수 있습니다.
from IPython.display import Audio
Audio(audio_numpy, rate=rate)
세부사항
모델 입력 및 출력, 학습 방법, 추론 및 성능 등에 대한 더 자세한 정보는 github 및 and/or NGC에서 볼 수 있습니다.
참고문헌
- Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
- WaveGlow: A Flow-based Generative Network for Speech Synthesis
- Tacotron2 and WaveGlow on NGC
- Tacotron2 and Waveglow on github