
import torch
model = torch.hub.load('mateuszbuda/brain-segmentation-pytorch', 'unet',
in_channels=3, out_channels=1, init_features=32, pretrained=True)
위 코드는 뇌 MRI 볼륨 데이터 셋 kaggle.com/mateuszbuda/lgg-mri-segmentation의 이상 탐지를 위해 사전 학습된 U-Net 모델을 불러옵니다. 사전 학습된 모델은 첫 번째 계층에서 3개의 입력 채널, 1개의 출력 채널 그리고 32개의 특징을 가집니다.
모델 설명
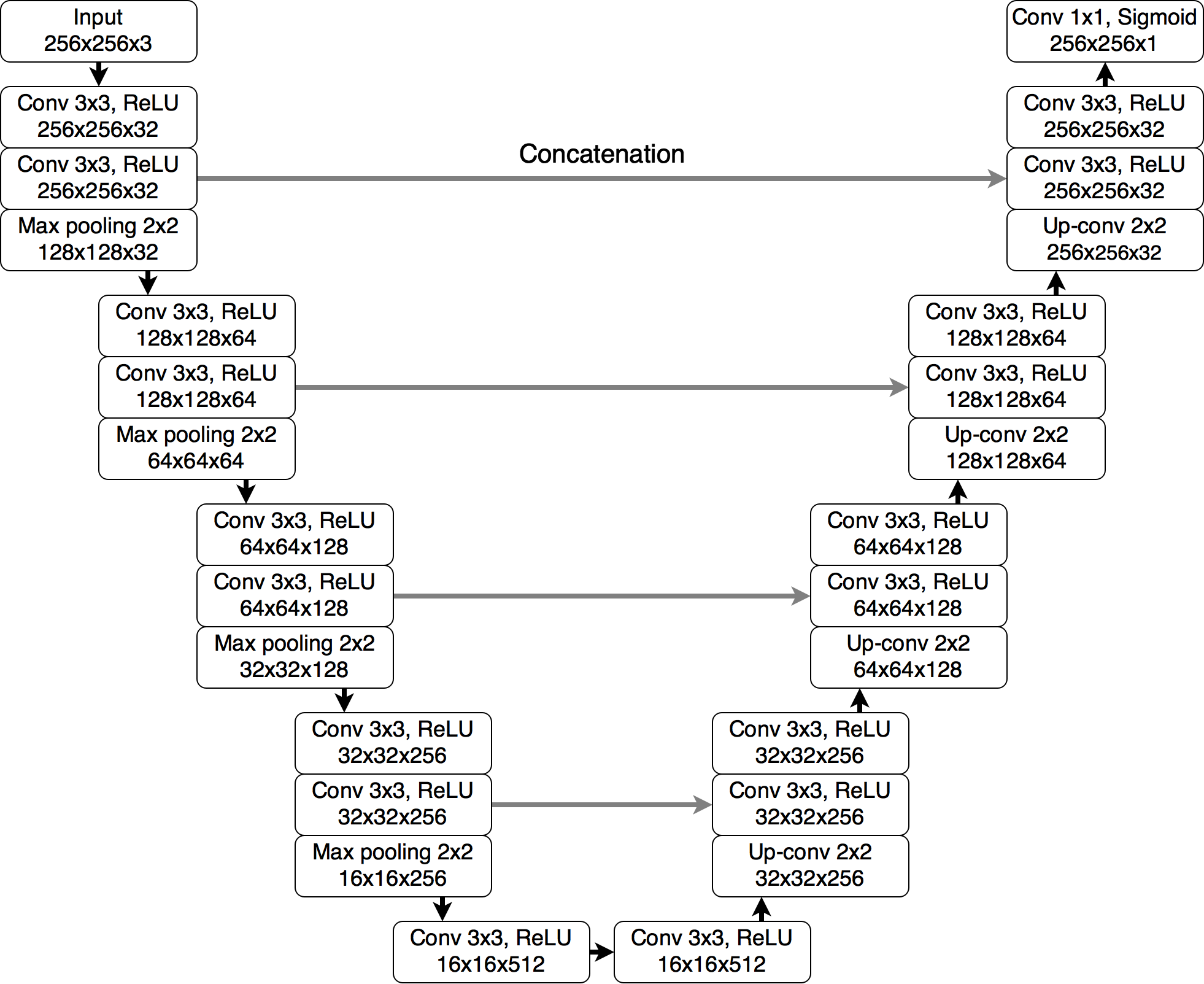
U-Net 모델은 배치 정규화 및 ReLU 활성 함수를 가진 두 개의 합성곱 계층, 인코딩 과정의 맥스 풀링(max-pooling) 계층 그리고 디코딩 과정의 업 컨볼루셔널(up-convolutional) 계층을 포함한 네 가지 단계의 블록으로 구성됩니다. 각 블록의 합성곱 필터 수는 32, 64, 128, 256개입니다. 병목 계층(bottleneck layer)은 512개의 합성곱 필터를 가집니다. 인코딩 과정의 계층에서 얻은 특징을 이에 상응하는 디코딩 과정의 계층에 합치는 스킵 연결(skip connections)이 진행됩니다. 입력 이미지는 pre-contrast, FLAIR 및 post-contrast 과정에서 얻은 3-채널 뇌 MRI 슬라이스입니다. 출력은 입력 이미지와 동일한 크기를 가지고 1-채널의 이상 탐지 영역을 확률적으로 나타냅니다. 아래의 예시처럼 임계 값을 설정하면 출력 이미지를 이진 분할 마스크로 변환할 수 있습니다.
예시
사전 학습된 모델에 입력되는 이미지는 3개의 채널을 가져야 하며 256x256 픽셀로 크기가 조정되고 각 볼륨마다 z-점수로 정규화된 상태여야 합니다.
# 예시 이미지 다운로드
import urllib
url, filename = ("https://github.com/mateuszbuda/brain-segmentation-pytorch/raw/master/assets/TCGA_CS_4944.png", "TCGA_CS_4944.png")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
import numpy as np
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
m, s = np.mean(input_image, axis=(0, 1)), np.std(input_image, axis=(0, 1))
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=m, std=s),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model = model.to('cuda')
with torch.no_grad():
output = model(input_batch)
print(torch.round(output[0]))
참고문헌
- Association of genomic subtypes of lower-grade gliomas with shape features automatically extracted by a deep learning algorithm
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- Brain MRI segmentation dataset