
import torch
model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x8d_wsl')
# 또는
# model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x16d_wsl')
# 또는
# model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x32d_wsl')
# 또는
#model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x48d_wsl')
model.eval()
모든 사전 학습된 모델은 동일한 방식으로 정규화된 입력 이미지를 요구합니다.
즉, H와 W가 최소 224의 크기를 가지는 (3 x H x W)형태의 3채널 RGB 이미지의 미니배치가 필요합니다.
이미지는 [0, 1] 범위로 불러온 다음 mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]를 이용하여 정규화해야 합니다.
다음은 실행 예시입니다.
# 파이토치 웹사이트에서 예시 이미지 다운로드
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# 실행 예시(torchvision이 요구됩니다.)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# GPU를 사용할 수 있다면, 속도 향상을 위해 입력과 모델을 GPU로 이동
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Imagenet의 1000개 클래스에 대한 신뢰도 점수를 가진, shape이 1000인 텐서 출력
print(output[0])
# 출력값은 정규화되지 않은 형태입니다. Softmax를 실행하면 확률을 얻을 수 있습니다.
print(torch.nn.functional.softmax(output[0], dim=0))
모델 설명
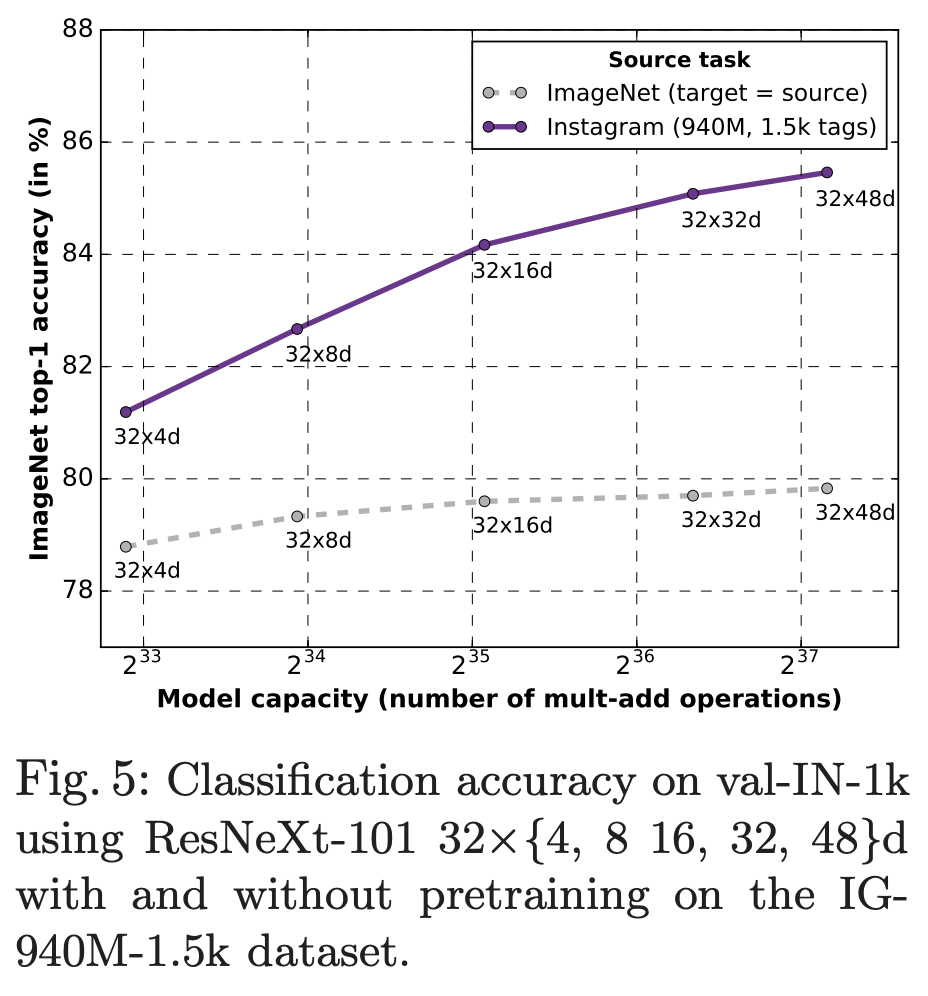
제공되는 ResNeXt 모델들은 9억 4천만개의 공공 이미지를 weakly-supervised 방식으로 사전 학습한 후 ImageNet1K 데이터셋을 사용해 미세 조정(fine-tuning)합니다. 여기서 사용되는 공공 이미지들은 1000개의 ImageNet1K 동의어 집합(synset)에 해당하는 1500개의 해시태그를 가집니다. 모델 학습에 대한 세부 사항은 “Exploring the Limits of Weakly Supervised Pretraining”을 참고해주세요.
서로 다른 성능을 가진 4개의 ResNeXt 모델이 제공되고 있습니다.
| Model | #Parameters | FLOPS | Top-1 Acc. | Top-5 Acc. |
|---|---|---|---|---|
| ResNeXt-101 32x8d | 88M | 16B | 82.2 | 96.4 |
| ResNeXt-101 32x16d | 193M | 36B | 84.2 | 97.2 |
| ResNeXt-101 32x32d | 466M | 87B | 85.1 | 97.5 |
| ResNeXt-101 32x48d | 829M | 153B | 85.4 | 97.6 |
ResNeXt 모델을 사용하면 사전 학습된 모델을 사용하지 않고 처음부터 학습하는 경우에 비해 ImageNet 데이터셋에서의 학습 정확도가 크게 향상됩니다. ResNext-101 32x48d 모델은 ImageNet 데이터셋을 사용했을 때 85.4%에 달하는 최고 수준의 정확도를 달성했습니다.