이 글은 PyTorch 공식 블로그의 글을 번역한 것입니다. 번역 글은 원문을 함께 표시합니다. 원문을 읽으시려면 여기를 클릭하세요. (This article is a Korean translation of the original post on the PyTorch official blog. Below translation includes the original text. To read the original post, click here.)
오늘 노트북과 데스크탑, 모바일에서 Llama 3와 3.1, 그리고 다른 대규모 언어 모델(LLM, Large Language Model)을 원활하고 고성능으로 실행하는 방법을 보여주는 라이브러리인 torchchat을 출시했습니다.
Today, we’re releasing torchchat, a library showcasing how to seamlessly and performantly run Llama 3, 3.1, and other large language models across laptop, desktop, and mobile.
이전 블로그 게시물에서는 네이티브 PyTorch 2에서 CUDA를 활용하여 LLM을 뛰어난 성능으로 실행하는 것을 보여드렸었습니다. Torchchat은 이를 더 많은 대상 환경과 모델, 실행 모드에서 확장했습니다. 또한, 내보내기(export)나 양자화(quantization), 평가(eval)와 같은 주요 기능들을 이해하기 쉬운 방식으로 제공하여 로컬 추론 솔루션을 구축하려는 사람들에게 시작부터 끝까지 알려(E2E story)드립니다.
In our previous blog posts, we showed how to use native PyTorch 2 to run LLMs with great performance using CUDA. Torchchat expands on this with more target environments, models and execution modes. Additionally it provides important functions such as export, quantization and eval in a way that’s easy to understand providing an E2E story for those who want to build a local inference solution.
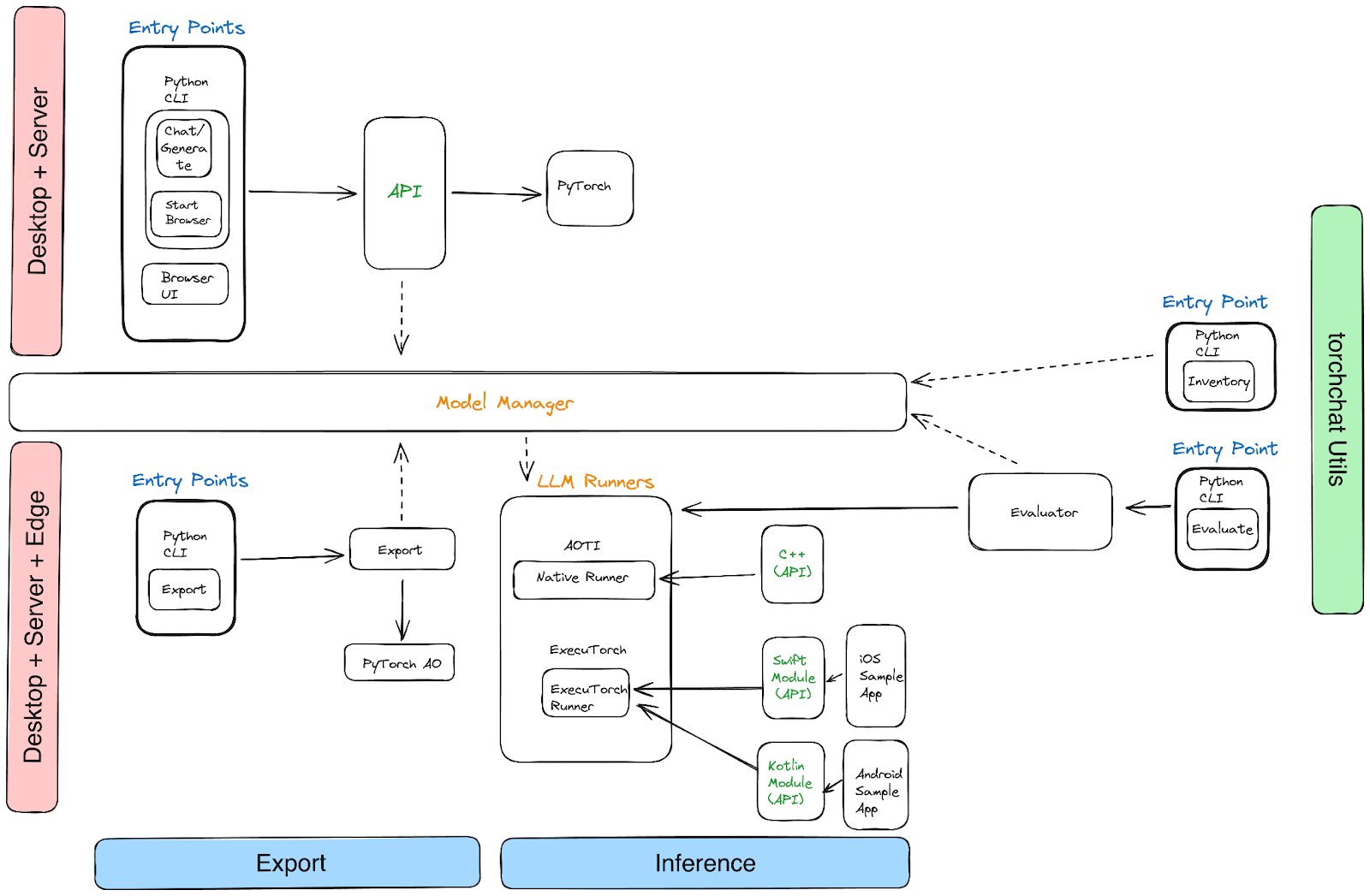
Torchchat은 3가지 영역으로 구성되어 있습니다:
You will find the project organized into three areas:
- Python: Torchchat은 Python CLI를 통해 호춣하거나 브라우저로 접근할 수 있는 REST API를 제공합니다.
- Python: Torchchat provides a REST API that is called via a Python CLI or can be accessed via the browser
- C++: 파이토치(PyTorch)의 AOTInductor 백엔드를 사용하여 데스크탑용 바이너리(desktop-friendly binary)를 생성합니다.
- C++: Torchchat produces a desktop-friendly binary using PyTorch’s AOTInductor backend
- 모바일 기기: Torchchat은 ExecuTorch 를 사용하여 온디바이스 추론을 위한 .pte 바이너리 파일을 내보냅니다.
- Mobile devices: Torchchat uses ExecuTorch to export a .pte binary file for on-device inference
성능 / Performance
다음 표는 다양한 구성에서의 Llama 3의 torchchat 성능을 살펴봅니다. Llama 3.1에서의 수치들은 곧 공개 예정입니다.
The following table tracks the performance of torchchat for Llama 3 for a variety of configurations.
Numbers for Llama 3.1 are coming soon.
애플 맥북 M1 Max 64GB 노트북에서 Llama3 8B Instruct 성능 / Llama 3 8B Instruct on Apple MacBook Pro M1 Max 64GB Laptop
| Mode | DType | Llama 3 8B Tokens/Sec |
| Arm Compile | float16 | 5.84 |
| int8 | 1.63 | |
| int4 | 3.99 | |
| Arm AOTI | float16 | 4.05 |
| int8 | 1.05 | |
| int4 | 3.28 | |
| MPS Eager | float16 | 12.63 |
| int8 | 16.9 | |
| int4 | 17.15 |
CUDA 및 Linux x86에서 Llama3 8B Instruct 성능 / Llama 3 8B Instruct on Linux x86 and CUDA
Intel(R) Xeon(R) Platinum 8339HC CPU @ 1.80GHz with 180GB Ram + A100 (80GB)
| Mode | DType | Llama 3 8B Tokens/Sec |
| x86 Compile | bfloat16 | 2.76 |
| int8 | 3.15 | |
| int4 | 5.33 | |
| CUDA Compile | bfloat16 | 83.23 |
| int8 | 118.17 | |
| int4 | 135.16 |
모바일에서 Llama3 8B Instruct 성능 / Llama3 8B Instruct on Mobile
Torchchat은 ExecuTorch를 통해 4-bit GPTQ를 사용하여 삼성 갤럭시 S23 및 아이폰에서 초당 8T 이상의 속도를 달성했습니다.
Torchchat achieves > 8T/s on the Samsung Galaxy S23 and iPhone using 4-bit GPTQ via ExecuTorch.
결론 / Conclusion
torchchat 저장소를 복제하여 사용해보시기를 권해드립니다. torchchat의 기능을 살펴보고, 파이토치 커뮤니티(PyTorch community)가 로컬 및 제약이 있는 기기(constrained device)에서 LLM을 실행할 수 있도록 역량을 강화하는 과정에 대한 여러분의 피드백을 공유해주시기 바랍니다. 생성형 AI와 LLM의 잠재력을 모든 기기에서 발휘할 수 있도록 함께 해주세요! 빠르게 반복하는 과정 중에 있으므로, 발견하시는 내용들은 이슈로 남겨주세요. 또한, 모델 추가를 비롯하여 지원하는 하드웨어, 새로운 양자화 기법, 성능 개선 등의 광범위한 범위에 걸친 커뮤니티의 기여를 기다리고 있습니다. 즐거운 실험되시길 바랍니다!
We encourage you to clone the torchchat repo and give it a spin, explore its capabilities, and share your feedback as we continue to empower the PyTorch community to run LLMs locally and on constrained devices. Together, let’s unlock the full potential of generative AI and LLMs on any device. Please submit issues as you see them, since we are still iterating quickly. We’re also inviting community contributions across a broad range of areas, from additional models, target hardware support, new quantization schemes, or performance improvements. Happy experimenting!
더 궁금하시거나 나누고 싶은 이야기가 있으신가요? 파이토치 한국어 커뮤니티에 참여해주세요!