이 글은 PyTorch 공식 블로그의 글을 번역한 것입니다. 번역 글은 원문을 함께 표시합니다. 원문을 읽으시려면 여기를 클릭하세요. (This article is a Korean translation of the original post on the PyTorch official blog. Below translation includes the original text. To read the original post, click here.)
기쁜 소식을 전해드립니다! 이제 PyTorch 2.4에서 Intel® Data Center Max 시리즈와 SYCL 소프트웨어 스택을 지원하여 학습과 추론 모두에서 AI 워크플로우의 속도를더 빠르게 할 수 있습니다. 이번 업데이트를 통해 최소한의 코딩 작업으로 일관된 프로그래밍 경험을 제공하며, 스트리밍 장치(streaming device)를 원활히 지원하기 위해 장치(device) 및 스트림(stream), 이벤트(event), 생성자(generator), 할당자(allocator), 가드(guard) 등을 포함한 PyTorch의 장치와 런타임 기능을 확장합니다. 이러한 개선 사항은 다양한 하드웨어(ubiquitous hardware)에 PyTorch를 배포하는 작업을 간소화하여, 다양한 하드웨어 백엔드를 통합하기 쉽게 만들어줍니다.
We have exciting news! PyTorch 2.4 now supports Intel® Data Center GPU Max Series and the SYCL software stack, making it easier to speed up your AI workflows for both training and inference. This update allows for you to have a consistent programming experience with minimal coding effort and extends PyTorch’s device and runtime capabilities, including device, stream, event, generator, allocator, and guard, to seamlessly support streaming devices. This enhancement simplifies deploying PyTorch on ubiquitous hardware, making it easier for you to integrate different hardware back ends.
Intel GPU 지원 업데이트로 PyTorch의 eager 및 graph 모드 모두를 지원하며, Dynamo Hugging Face 벤치마크를 완전히 실행할 수 있습니다. Eager 모드는 이제 SYCL로 구현된 일반 Aten 연산자를 포함합니다. 가장 성능이 중요한(performance-critical) graph와 연산자는 oneAPI Deep Neural Network Library (oneDNN) 및 oneAPI Math Kernel Library (oneMKL)을 사용하여 최적화되었습니다. Graph 모드(torch.compile)는 이제 Intel GPU 백엔드가 활성화되어 Intel GPU에 대한 최적화를 구현하고 Triton을 통합할 수 있습니다. 또한, FP32, BF16, FP16 및 자동 혼합 정밀도(AMP, Automatic Mixed Precision)와 같은 데이터 타입(data type)을 지원합니다. Kineto와 oneMKL 기반으로 개발 중인 파이토치 프로파일러(PyTorch Profiler)는 곧 출시될 PyTorch 2.5 릴리스에서 제공될 예정입니다.
Intel GPU support upstreamed into PyTorch provides support for both eager and graph modes, fully running Dynamo Hugging Face benchmarks. Eager mode now includes common Aten operators implemented with SYCL. The most performance-critical graphs and operators are highly optimized by using oneAPI Deep Neural Network Library (oneDNN) and oneAPI Math Kernel Library (oneMKL). Graph mode (torch.compile) now has an enabled Intel GPU back end to implement the optimization for Intel GPUs and to integrate Triton. Furthermore, data types such as FP32, BF16, FP16, and automatic mixed precision (AMP) are supported. The PyTorch Profiler, based on Kineto and oneMKL, is being developed for the upcoming PyTorch 2.5 release.
PyTorch에 Intel GPU를 통합하기 위한 현재와 앞으로 계획된 프론트엔드(front-end) 및 백엔드(back-end) 개선 사항을 살펴보세요.
Take a look at the current and planned front-end and back-end improvements for Intel GPU upstreamed into PyTorch.
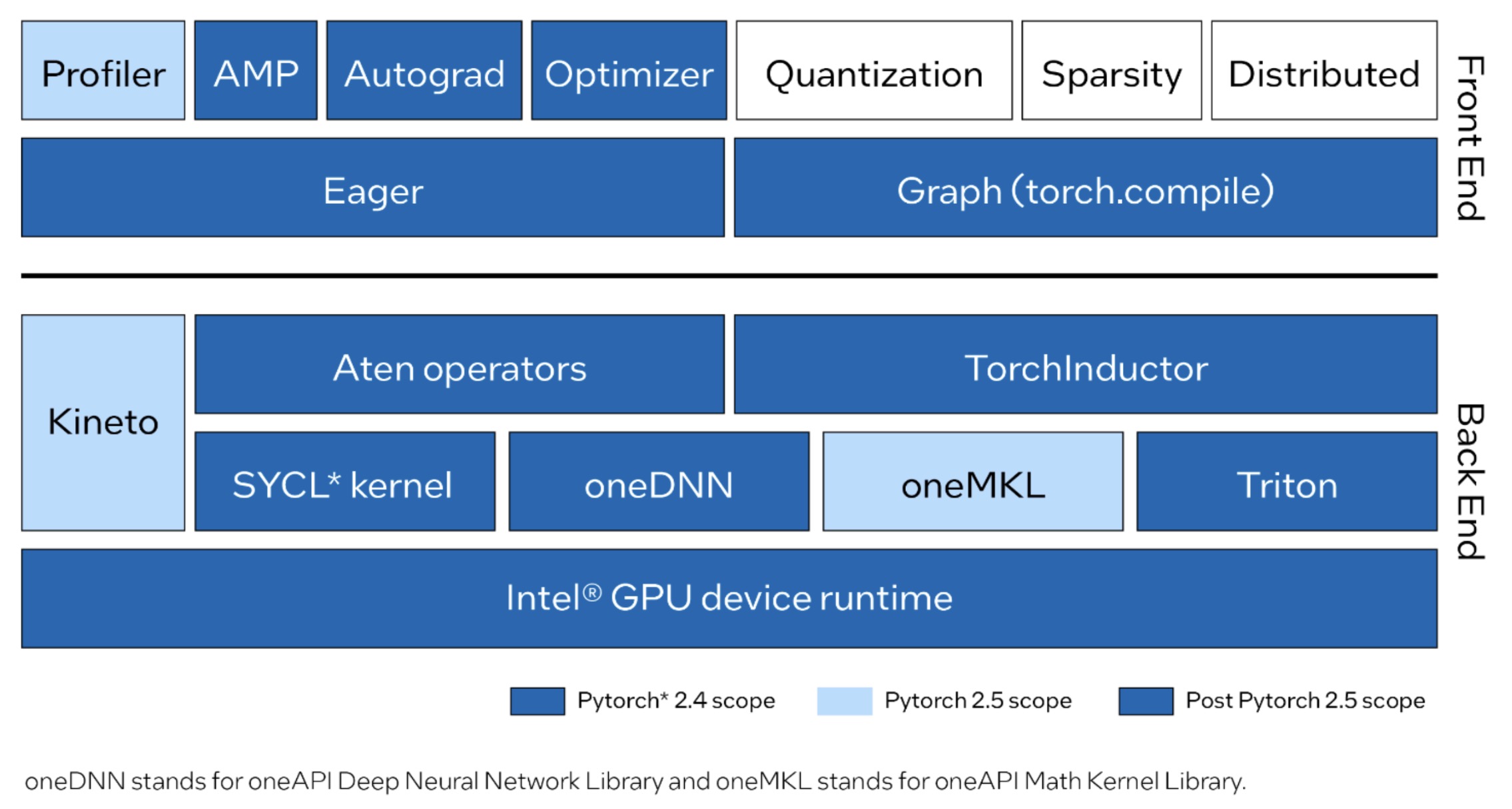
Linux에서의 PyTorch 2.4는 다른 하드웨어와 동일한 사용자 경험을 유지하면서 학습 및 추론 시에 Intel Data Center GPU Max 시리즈를 지원합니다. CUDA에서 코드를 이전(migration)하는 경우, 장치 이름을 cuda에서 xpu로만 변경하기만 하면 최소한의 변경으로 Intel GPU에서 기존 애플리케이션을 실행할 수 있습니다. 예를 들어:
PyTorch 2.4 on Linux supports Intel Data Center GPU Max Series for training and inference while maintaining the same user experience as other hardware. If you’re migrating code from CUDA, you can run your existing application on an Intel GPU with minimal changes—just update the device name from
cudatoxpu. For example:
# CUDA 코드 / CUDA Code
tensor = torch.tensor([1.0, 2.0]).to("cuda")
# Intel GPU용 코드 / Code for Intel GPU
tensor = torch.tensor([1.0, 2.0]).to("xpu")
시작하기 / Get Started
Intel® Tiber™ Developer Cloud에서 Intel Data Center GPU Max 시리즈에서 PyTorch 2.4를 사용해보세요. 환경 설정, 소스 빌드 및 예제를 살펴보세요. 무료 Standard 계정을 만드는 방법은 시작하기를 참고하시고, 다음의 단계를 수행하세요:
Try PyTorch 2.4 on the Intel Data Center GPU Max Series through the Intel® Tiber™ Developer Cloud. Get a tour of the environment setup, source build, and examples. To learn how to create a free Standard account, see Get Started, then do the following:
- 클라우드 콘솔(Cloud Console)에 로그인하세요.
- 학습(Training) 섹션에서 PyTorch 2.4 on Intel GPUs 노트북을 엽니다.
- 노트북에서 PyTorch 2.4 커널(kernel)이 선택되어 있는지 확인하세요.
- Sign in to the cloud console.
- From the Training section, open the PyTorch 2.4 on Intel GPUs notebook.
- Ensure that the PyTorch 2.4 kernel is selected for the notebook.
요약 / Summary
PyTorch 2.4에서 Intel Data Center GPU Max 시리즈에서 AI 워크로드를 가속화하기 위한 초기 지원(initial support)을 시작합니다. Intel GPU를 사용하면 지속적인 소프트웨어 지원과 통합 배포(unified distribution), 그리고 동기화된 릴리즈 일정(synchronized release schedule)을 통해 원활한 개발 경험을 제공합니다. PyTorch 2.5에서는 이 기능을 Beta 등급(quality)이 되도록 개선할 예정입니다. 2.5에서 계획된 기능은 다음과 같습니다:
PyTorch 2.4 introduces initial support for Intel Data Center GPU Max Series to accelerate your AI workloads. With Intel GPU, you’ll get continuous software support, unified distribution, and synchronized release schedules for a smoother development experience. We’re enhancing this functionality to reach Beta quality in PyTorch 2.5. Planned features in 2.5 include:
- Eager 모드에서 더 많은 Aten 연산자 및 완전한 Dynamo Torchbench 및 TIMM 지원.
- torch.compile에서 완전한 Dynamo Torchbench 및 TIMM 벤치마크 지원.
- torch.profile에서 Intel GPU 지원.
- PyPI wheels 배포.
- Windows 및 Intel Client GPU 시리즈 지원.
- More Aten operators and full Dynamo Torchbench and TIMM support in Eager Mode.
- Full Dynamo Torchbench and TIMM benchmark support in torch.compile.
- Intel GPU support in torch.profile.
- PyPI wheels distribution.
- Windows and Intel Client GPU Series support.
PyTorch에서의 Intel GPU 지원과 관련한 새로운 기여에 대해 커뮤니티에서 평가해주시기를 기대합니다.
We welcome the community to evaluate these new contributions to Intel GPU support on PyTorch.
리소스 / Resources
감사의 말 / Acknowledgments
기술적 토론과 인사이트를 제공해주신 PyTorch 오픈소스 커뮤니티에 감사드립니다: Nikita Shulga와 Jason Ansel, Andrey Talman, Alban Desmaison, Bin Bao.
We want thank PyTorch open source community for their technical discussions and insights: Nikita Shulga, Jason Ansel, Andrey Talman, Alban Desmaison, and Bin Bao.
또한, 전문적인 지원과 안내를 제공해주신 PyTorch의 기여자(collaborator)들에게 감사드립니다.
We also thank collaborators from PyTorch for their professional support and guidance.
1 GPU 지원을 활성화하고 성능을 향상시키기 위해 Intel® Extension for PyTorch를 설치하는 것을 권장합니다.
1 To enable GPU support and improve performance, we suggest installing the Intel® Extension for PyTorch
더 궁금하시거나 나누고 싶은 이야기가 있으신가요? 파이토치 한국어 커뮤니티에 참여해주세요!